Error Propagation Calculator
A reflection on the first time I realized I could. Check out the website and the project on GitHub .
Table of Contents:
It starts with: why not?
This whole project came about during one of the many “dude, we need to get rich” conversations between me and my good friend João Rei.
We knew we had to solve a real world problem. Here’s why calculating error propagations was one of the first things that popped up.
Understanding the problem: why it sucks
For context, calculating error propagations was a very common task on our bachelor’s physics laboratories.
The theory
Imagine you are trying to experimentally estimate some value $F$ from measurements $x$, $y$, $z$. You could write it as:
$$ F = F(x,y,z) $$
Now, each of those measurements has an associated experimental error (or uncertainty, whatever, I’ll leave the correct terms for the physicists): $\delta x$, $\delta y$, $\delta z$. These will have an impact on the error of $F$.
One way to quantify this impact is to take a first order approach and sum the max error across all variables. Basically saying “yeah, $F$ is linear around $x$, so if we move $F$ by $\delta x$ we should get a good estimate of $\delta F$”.
Mathematically:
$$ \delta F = \sum_{x_i} |\frac{d F}{d x_i}|\delta x_i $$
In the example above:
$$ \delta F(x,y,z) = |\frac{d F}{d x}|\delta x + |\frac{d F}{d y}|\delta y + |\frac{d F}{d z}|\delta z $$
Reality
On the real world these error expressions can be huge and messy.
To make matters worse, you’d often have your measurements on an Excel spreadsheet, meaning you’d have to translate this whole mess onto an Excel formula and replace all the variables with their appropriate cells.
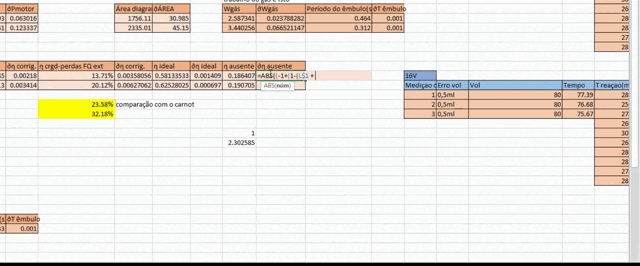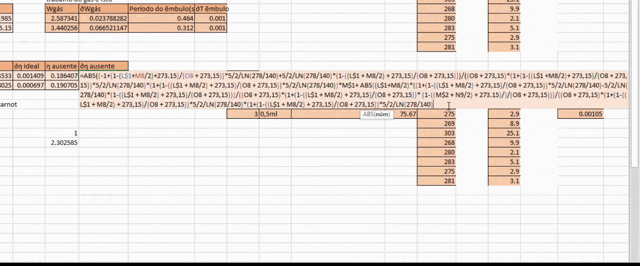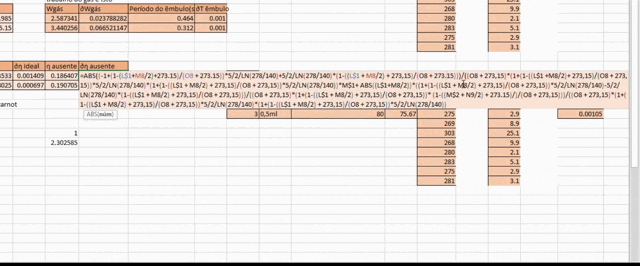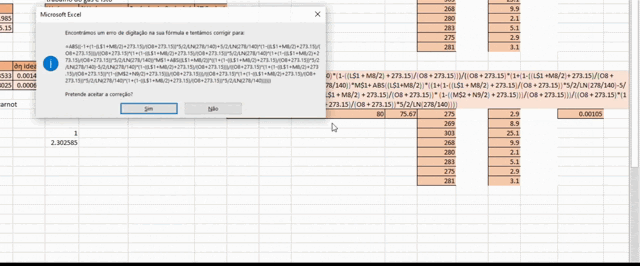
Excel Pain
Plus, you had to repeat this process multiple times per lab for different values, all with different expressions and corresponding cells!
All of these factors combined made for a really unpleasant experience, and being the one designated to do this task was akin to drawing the shortest straw on doomed mission.
The solution
To solve this problem efficiently, we needed a program to do the following:
- take in any math expression with common operators
- automatically detect all the variables present
- give the user a chance to mark differentiation variables or constants
- give the user the chance to change the name of a variable and it’s error (for example, to excel cells)
- return the error propagation expression, which could be copy pasted into Python, Excel or Latex
We also wanted to make it as accessible and portable as possible, so a Web application was the perfect target!
Why not just do it?
There’s a how (and a why not)
Simple Python implementation
We quickly cooked together an implementation using Python’s SymPy library.
First, we use SymPy’s parse_expr
to get the expression object.
import sympy as sp
expr = sp.parsing.sympy_parser.parse_expr(expr_string)
Next, we can get all the variables in the expression with:
variable_set = expr.free_symbols
Finally, we can loop through all the (usable) variables in the expression and construct the error propagation string. The partial derivative can be calculated using diff()
method.
for index, var in enumerate(variable_set):
if (usable_list[index]):
final = final + f" + abs({str(expr.diff(var))})*δ{var}"
Great! Now we can just hook it up to a FastAPI backend and be done with it. It’s just that simple!
Or is it?
Narrator voice: “it wasn’t, in fact, that simple”
As it turns out, this implementation was really not a good idea for various performance and security reasons.
Processing time
The first issue that caught our attention was the (possibility of) high processing times.
For regular expected use™ this wasn’t a problem, in only took a couple of seconds maximum. However, the user is evil and could just input the most diabolical of expressions and take the whole server hostage for minutes. Really not ideal.
Limiting number of characters
We thought about limiting the number of characters the user could input.
However, this was not suitable and would end up sacrificing the quality of our service too much, since mundane expressions could be long due to long variable names. Personally, I also hate this type of hard-coded solutions.
Most importantly, as we would soon find out, it didn’t take a lot of characters to stall (or kill for that matter) our server.
Multi-threading
To mitigate the possible long processing times, we tried implementing a multi-threaded approach, where each error propagation request was computed on a different Python Thread with a maximum processing time, after which the Thread was killed.
This seemed like a nice solution, however we had neither the time nor experience to make it work.
Said implementation ended up being extremely janky. Particularly, if the input expression was something like 1000^1000000000^1000000, it would stall trying to evaluate that expression and for some reason the worker thread refused to die no matter what.
Wait, it would evaluate the expression? Oh no…
The reveal: evil eval
If high processing time was potentially service breaking, this was a whole other level of threat to the service itself. Contrary to what this user said on StackOverflow
, Sympy’s parse_expr()
method still seems to use python’s built-in eval() (
source code
), even with evaluate parameter set to False.
Python’s eval() is a very powerful tool that allows for the execution of arbitrary code as a Python expression. I’m not gonna pretend to be cybersecurity expert, but I had participated in a few CTF events with Python Jailbreaks and knew better than to try to fight against this security vulnerability.
Once I tried calculating the error propagation of __import__('os').system('reboot') and the my computer just, well, rebooted, I knew this was not gonna work.
At the end of the day, we just didn’t have the necessary skill or resources to implement a usable backend. The potential processing complexity and security risks involved made it just not worth it. If only there was a way to pass this computational burden onto the users themselves.
The great rewrite
Wait it’s all JavaScript?
So yeah, we rewrote it all in JavaScript.

It's all a bunch of js
Luckily for us, it wasn’t even that complicated. The math.js library is surprisingly complete, and it even includes a function derivative method . The only true adaptation that had to be made was the way we get all the variables in the expression, as there was no built-in support back then ( source code ):
export function get_variables(exp_string) {
. . .
const node = parse(exp_string);
let variables = node
.filter(function (node) {
return node.isSymbolNode && !trigFunctions.includes(node.name);
})
.map(function (node) {
return node.name;
});
return variables;
}
All this does is filter all the nodes in the tree like structure generated by parse(exp_string) and extracts the name of the nodes that are not operators or trigonometric functions, i.e. the variables.
Pros and Cons
We can compare the pros and cons of the new JavaScript implementation (vs the old Python one).
| Pros | Cons |
|---|---|
| + Reduced complexity | - Loss in performance |
| + Increased robustness | - Expression simplification not as good |
| + No constraints on user input | |
| + Easy to host |
In the end, moving all the processing to the front-end was on overall a positive!
We gave up speed (the js implementation was anywhere from 2 to 5x slower) and better expression simplifications for a simpler and a lot more robust alternative, with near infinite scaling. As an added bonus, the fact that it did not require a backend made it perfect to host on one of the many static website free hosting platforms!
On Web technologies and YouTube brainrot
So far, this post has been mostly dedicated to the inner workings of the error propagation algorithm itself. However, I’d like to also briefly highlight one of the main issues I faced as a first time web developer: there are (seemingly) way too many options!
Decisions
When starting out this project, the first thing I did was look up what tools I should use on YouTube. I probably clicked on one of the many “top 10 web/tech stacks of 202*” and, just like that, I was hooked. I must have spent days watching every single tier list, every review, every pros and cons and reading every single comment on all the YouTube, Reddit and Blog posts, agonizing over the apparently life changing decision that was choosing a front-end framework.
In the process, I ended up adding a lot of technologies that were frankly useless for my use case, like TypeScript. A confession, fellow readers: even today I don’t really know the difference between it and JavaScript! But I absolutely “had to have it” according to all the experts.
It really isn’t all that.
I still think doing research is important, and don’t regret (finally) choosing Svelte (quite like the thing), but as a beginner that time was probably better spent learning the fundamentals of HTML, CSS and maybe JavaScript. After all, how can one really comprehend what a modern framework brings to the table if they never really played with default settings?
Indecisions
This second problem came as a direct consequence of the first: I started second guessing the tools I chose.
After investing so much time analysing all the possible options, everything had to be perfect. Every time I hit a small road block the immediate reaction was to blame the software and myself for choosing it, when in reality I should have just been blaming myself for being bad at programming.
For example, when the CSS style sheets got “messy” (it wasn’t even that bad), I introduced Tailwind CSS , which is great, I like it, but now it’s the middle of development and I’m in a call with my partner being like “no, no, you don’t understand this is so much better, this is the future, totally worth learning trust me bro™”
Finding peace in compromise
It can be quite easy to find yourself obsessing over everything that is new.
When starting, it might be a good idea to focus on the basics first. Only by using something is it possible to understand it’s strengths and pitfalls.
Further, it is important to understand when to try a different approach, like when we had to rewrite the Python backend and move it to the frontend. But perhaps equally as important is to realize when it is not worth the time to do it.
In the end, you might end up finding that the defaults are all you need.
The good ending
Doing this project was really cool. I learned a lot and it’s great to see the website still in use by my fellow colleagues to this day. We even won an award for it!
Most of all I learned that I had what it took to find problems and offer a solution for the betterment of the community.
— José Duarte Lopes